
Explore Google’s research on end-to-end query term weighting and how this model has the potential to enhance search rankings in the future.
Seth Godin, in 2005, highlighted the complexity of the search landscape.
It’s worth noting that while SEO is undoubtedly challenging, the task becomes even more daunting when you consider the constantly evolving user preferences, the continuous technological advancements, the relentless competition, and the added layer of SEO experts seeking to understand and optimize for search algorithms.
Now, imagine a scenario where the core technologies needed for progress come with their own constraints and substantial expenses.
For the authors of the recently published paper titled “End-to-End Query Term Weighting,” this presents an exciting opportunity to demonstrate their expertise and innovation.
Deciphering End-to-End Query Term Weighting
End-to-end query term weighting is an approach in which the model computes the weight of each term within a query as an integral part of its overall processing, eliminating the need for manual programming, conventional term weighting techniques, or the reliance on separate models.
What does this illustration depict?

In this visual representation, we observe a fundamental distinction in the model outlined in the paper (specifically Figure 1).
On the right side of the standard model (labeled as 2), we observe a structure identical to what we find in the proposed model (referred to as 4).
Both pathways start with the corpus, which represents the complete set of documents in the index. This corpus leads to the documents, which, in turn, lead to the individual terms within them.
This depiction illustrates the actual hierarchical flow within the system, although it can be conceptually understood in reverse, starting from the top.
Beginning with individual terms, the system seeks documents containing these terms, and these documents are drawn from the corpus encompassing all known documents.
Now, directing our attention to the lower left section (labeled as 1) within the standard Information Retrieval (IR) architecture, we notice the absence of a BERT layer.
In this scenario, the query (in this case, “Nike running shoes“) enters the system, and the weights associated with each term are computed independently of the model before being fed into it.
In the illustration on the right-hand side, which represents the term-weighted version, the query “Nike running shoes” enters BERT (specifically Term Weighting BERT, or TW-BERT), where it undergoes a process to assign optimal weights tailored to that particular query.
Following this point, both pathways share a similar progression. A scoring function is applied, leading to the ranking of documents.
However, a critical distinction arises with the new model—this distinction is the focal point of the entire process: the ranking loss calculation.
The significance of the weights being determined within the model becomes evident when considering this calculation.
To gain a better understanding of this concept, it’s essential to briefly delve into the realm of loss functions, as comprehending these functions is crucial to grasping the underlying principles at play here.
What constitutes a loss function in machine learning?
Essentially, a loss function serves as a measure of the degree of error inherent in a system’s learning process, with the system endeavoring to minimize this error and approach a loss value as close to zero as possible.
To illustrate this concept, consider a model designed to predict house prices.
Suppose the model, based on the input data about a house, estimates its value at $250,000, but the house sells for $260,000.
In this scenario, the disparity between the model’s estimate and the actual sale price is regarded as the loss, typically calculated as an absolute value.
Across a multitude of examples, the model is trained to reduce this loss by adjusting the weights assigned to various parameters it considers, such as square footage, number of bedrooms, yard size, proximity to schools, and so on, until it achieves the best possible prediction.
Now, circling back to the context of query term weighting, the critical focus lies in the presence of a BERT model responsible for assigning weights to terms downstream of the ranking loss calculation.
In simpler terms, in conventional models, term weighting occurred independently of the model itself and could not therefore adapt to the overall model’s performance.
It couldn’t learn how to refine term weightings based on its performance.
However, in the proposed system, this paradigm shifts. Term weighting is conducted within the model itself.
Consequently, as the model strives to enhance its performance and minimize the loss function, it gains the capability to fine-tune term weightings as part of the process.
In essence, term weighting becomes an integral component of the model’s optimization.
Regarding the use of ngrams in TW-BERT, it’s important to note that this model operates not on individual words but rather on ngrams.
The rationale behind this choice becomes apparent when examining the query “Nike running shoes.”
If we were to assign weights solely to individual words in the query, a page containing references to “Nike,” “running,” and “shoes” might rank well, even if it primarily discusses “Nike running socks” and “skate shoes.”
Traditional information retrieval (IR) methods rely on query and document statistics and may encounter issues where pages with similar keyword mentions rank prominently.
Previous attempts to address this challenge have focused on factors like co-occurrence and word order.
In the proposed model, ngrams receive weightings similar to how individual words were treated in the previous example.
This approach results in a more nuanced and context-aware representation of the query, enhancing the model’s ability to understand and retrieve relevant information.
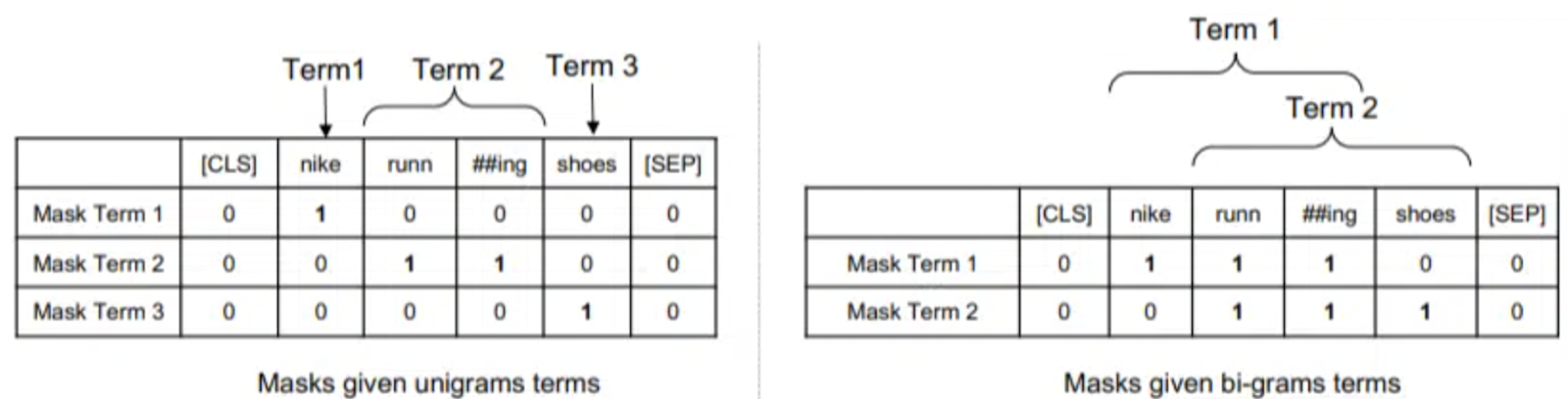
On the left side, we observe the application of weight to the query in the form of uni-grams (1-word ngrams), while on the right, bi-grams (2-word ngrams) are utilized.
Because the weighting process is integrated into the system, it can undergo training encompassing all possible permutations, thereby enabling the determination of the most suitable ngrams and their corresponding optimal weights.
This stands in contrast to the reliance solely on statistical measures like frequency.
Zero-shot capability is a noteworthy aspect of this model. The authors conducted evaluations in scenarios where the model had not been specifically fine-tuned for the given tasks, effectively making it a zero-shot test.
They conducted these evaluations on various datasets, including:
- The MS MARCO dataset pertains to Microsoft’s collection of documents and passages for ranking.
- The TREC-COVID dataset encompasses articles and studies related to COVID-19.
- Robust04, which consists of news articles.
- Common Core, a dataset comprising educational articles and blog posts.
- It’s important to note that they had a limited number of evaluation queries and conducted no fine-tuning for these specific domains.
The results obtained from these zero-shot tests were as follows:
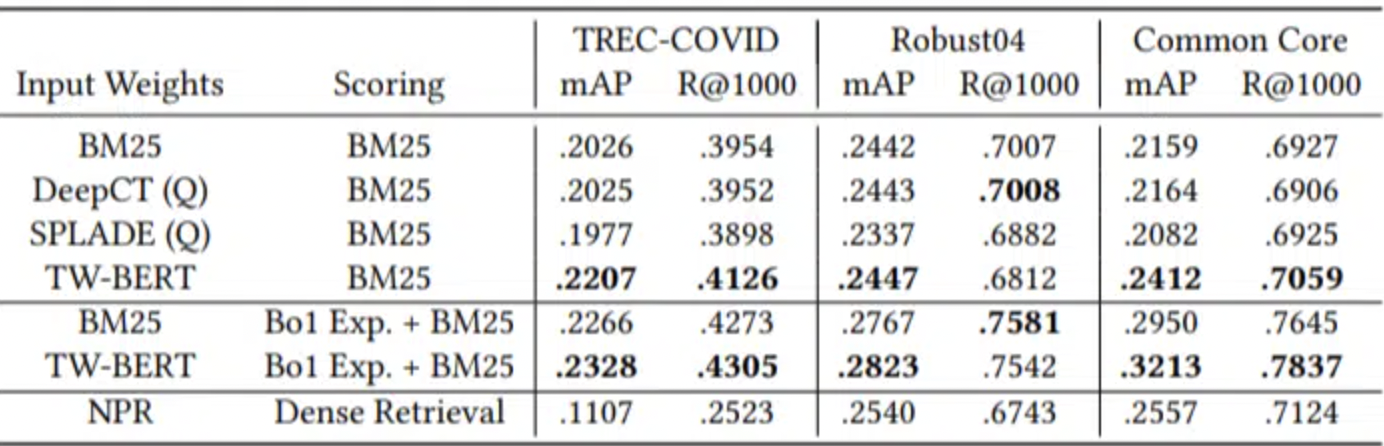
It achieved superior performance in most tasks, particularly with shorter queries consisting of 1 to 10 words.
Moreover, it’s worth noting that it offers a simplified integration process, making it highly accessible for use.
While describing it as “plug-and-play” may be somewhat oversimplified, the authors clarify that aligning TW-BERT with search engine scorers significantly reduces the modifications required to incorporate it into existing production applications.
In contrast, implementing other deep learning-based search methods would necessitate additional infrastructure optimization and hardware upgrades.
The weights learned by TW-BERT can be effortlessly employed by standard lexical retrievers and other retrieval techniques like query expansion.
What does this imply for you, then?
When it comes to machine learning models, it can be challenging to predict their exact impact on your role as an SEO professional, aside from visible deployments like Bard or ChatGPT.
However, a variant of this model will probably be deployed, given its performance enhancements and straightforward integration (assuming the claims hold).
In essence, this represents a significant quality-of-life improvement within Google’s ecosystem. It not only enhances rankings and zero-shot results but does so with cost-effectiveness in mind.
The bottom line is that, if implemented, this advancement promises more consistent and improved results. And that’s certainly welcome news for SEO professionals.


