Last Updated on 23/07/2026
As an SEO specialist, you may have spent a significant amount of effort optimizing fresh material but are still not meeting your ranking potential. It might be because you neglect an unseen threat: index bloating.
Index bloating poses issues for both search engines and website owners. It hampers search engine algorithms’ effort to recognize useful information, resulting in fewer site crawls.
Furthermore, it buries high-quality material behind less useful pages, reducing your site’s exposure and total ranking potential.
Fortunately, addressing index bloating is simple.
We will look into index bloating, how it impacts crawl budgets, and practical solutions to increase your website’s online exposure.
What Is Index Bloat?
Index bloat occurs when your website contains dozens, hundreds, or thousands of low-quality pages indexed by Google that offer no use to potential visitors.
This leads search crawlers to spend too much time searching through irrelevant pages on your site rather than focusing their efforts on sites that benefit your business. It also provides a terrible user experience for your website’s visitors.
Index bloat occurs frequently on eCommerce sites with a huge number of goods, categories, and user reviews. Low-quality pages that search engines index might overwhelm the site due to technical difficulties.
In brief, index bloat causes your site to slow down and waste crawl funding. Maintaining a clean website ensures that search engines index just the URLs you want users to find.
Index Bloating in Action: An Example
A few years ago, we planned to work on an eCommerce site with roughly 10000 pages.
When we visited Google Search Console, we were startled to find that Google had indexed 38000 pages for our domain. That was far too high given the size of the location.
(Hint: You can discover these figures for your site under “Search Console” > “Indexing” > “Pages.”)
That number has increased considerably in a short period. Initially, Google Analytics indexed 16000 pages.
What was going on?
The site’s software created hundreds of superfluous product pages.
On a high level, if the website sold out of inventory for a brand (which happened frequently), the pagination algorithm generated hundreds of additional pages.
As a result of the bug, website indexation skyrocketed and SEO performance suffered.
Give this a quick read: How To Do Deindexing? Effective Methods Are Explained Here!
Index Bloat: Why It Matters?

Index bloat inflates your search engine presence with content that provides no purpose or is irrelevant to visitors.
When search bots index these irrelevant pages, it is:
- Search engines have a more difficult time ranking your site. Search crawlers must comprehend your website to accurately match content to user requests and rank it. Pages that lack a clear, logical purpose make it more difficult for Google and other search engines to comprehend and obtain information.
- Negatively impacts search engine ranks. When pages with comparable content target the same keywords, they compete against one another. Low-quality pages or duplicate content may fail to rank or interest readers, lowering your site’s overall authority.
- Inefficient use of the crawl budget. Index bloat causes search bots to squander their limited crawl budget acquiring material that Google does not require. This diverts time and resources away from the pages you want to rank for.
How to Diagnose Index Bloat?

The Google Search Console Coverage Report is one of the quickest and most dependable techniques to discover page types that cause index bloat.
The URLs that are indexed but not submitted to the XML sitemap, assuming your sitemap follows SEO best practices and contains only SEO-relevant URLs.
Use a boundless crawling tool to find the number of indexable URLs if your XML sitemaps aren’t optimally representing legitimate pages.
If you have many more legitimate pages than crawled URLs, you are most certainly experiencing index bloat.
Do not use the site: search advanced operator to count the number of indexed pages; it is quite inaccurate.
Once you’ve found low-value pages to deindex, cross-reference the URLs with Google Analytics data to determine the expected impact on organic traffic.
Because of their nature, they usually have no detrimental impact, but it’s essential to double-check before proceeding with large-scale deindexing.
How Index Bloating Impacts SEO Performance?

With over 1.13 billion websites online, search engines have a restricted “crawl budget” for each one. It means they can only view and analyze a particular number of pages in a given time frame.
Your site’s key pages are crawled but not indexed due to index bloat, and if your budget runs out, the indexing process will cease.
As a result, your content will take longer to appear on SERPs, thus harming your website’s ranks and decreasing conversion rates.
Your website has a limited number of pages indexed by Google, aside from crawl budget constraints.
This leaves great material untouched and perhaps little known. A high-quality page that receives 7,000 views per month may receive only 2,500 if Google crawls the unwanted pages that compete for the same traffic.
Index bloating can lead to lower click-through rates and a bad user experience.
When users encounter pages from an excessively large index, they have to sift through more low-quality results to find what they’re looking for, leading to more bounces and fewer clicks on your site.
Over time, this reduces your CTR, causing Google to lose faith in you and rank you lower.
Here is an outline of how index bloating affects SEO health:
- Wasting an expensive crawl budget on pages that contribute nothing to your business’s growth.
- Hurt rankings, lower traffic, and eventually diminish conversion rates.
- Decreasing CTR and creating terrible UX.
In a nutshell, index bloating significantly delays your SEO progress while quietly reducing the effectiveness of your greatest content. It’s like trying to get out of quicksand; it draws you down with each step.
How To Fix Index Bloat?
a. Conduct an Index Audit
Explore Search Console and Google Analytics to determine the value of indexed pages. Sort into:
- Essential content to maintain
- Middling fluff to strengthen or solidify
- Useless zombie pages to delete or reroute
By segmenting pages in this way, you can reveal consolidation and pruning possibilities, enabling you to shift historical content equity easily. The ongoing link traffic to the regions of your site that best meet user demands.
This technique will also show holes in the site design that require new content placement.
b. Remove Internal Links
If you intend to noindex your material, deleting internal connections to it will reduce Google’s ability to detect and index it.
Because Google utilizes internal links to find new material on your site, removing that channel causes Google to focus its attention on other internal connections on your page and scan them instead.
If you wish to remove your unnecessary pages, deleting internal connections to those pages will lessen the likelihood of broken links and allow you to link to more relevant information that you want Google to find.
c. 301 redirects
If your website has many URLs that contain the same or comparable information, use 301 redirects to the desired canonical version of the page.
This will direct link equity and ranking signals to the canonical URL, eliminating index bloat from duplicate sites.
d. Set the Proper Canonical Tags
Google prioritizes sites containing canonical tags in the header section (<link rel=”canonical” href=”<original page URL>) for indexing.
This prevents duplicate pages and consolidates link equity, redirecting it to the primary page instead.
e. Update or Install robot.txt

If your website does not already have a robot.txt file, create one. To ensure that search crawlers reach the correct sites, it is recommended that we regularly review and update current robots.txt files.
A robots.txt file prevents search engine bots from accessing subdirectories. For example, we prevent Google from crawling user-generated search results.
If our robots.txt file did not accomplish this, Google might access, crawl, and index thousands of pages that we do not want to appear in search results, depleting its crawl budget.
f. Use Google Search Console’s URL Removals Tool
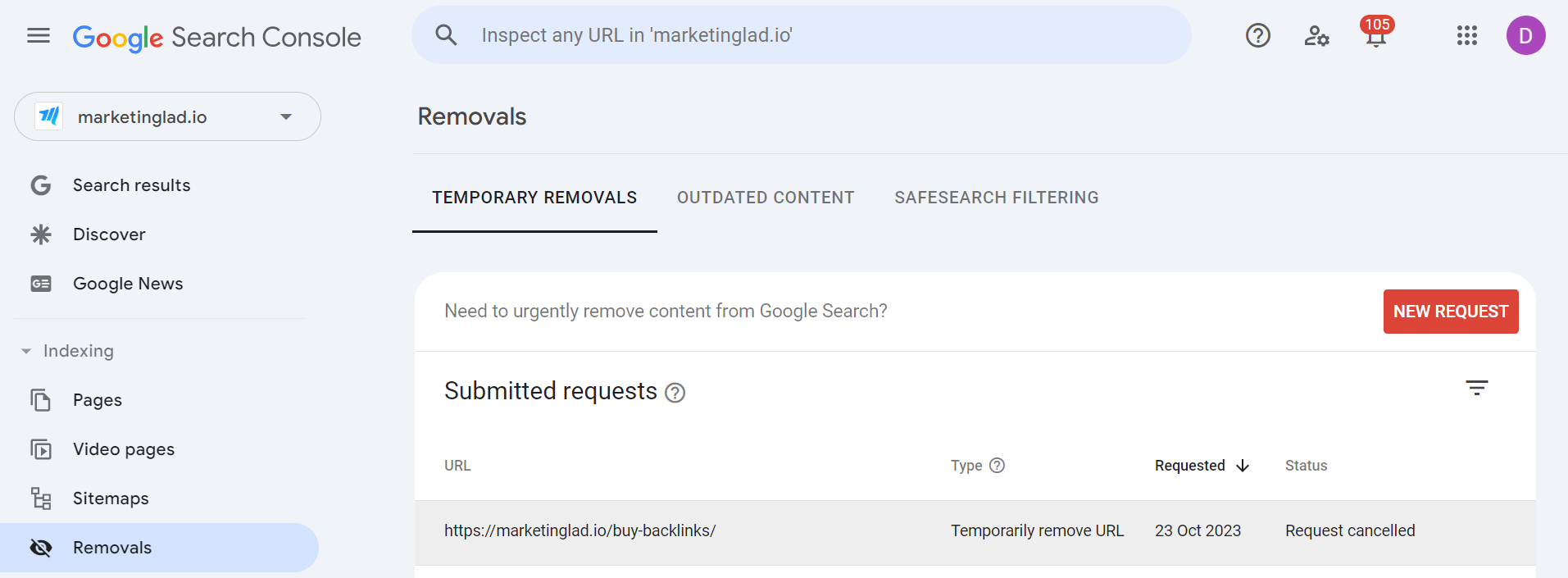
However, utilize this procedure just as a temporary remedy. When you request Google, it immediately deletes the pages from its index (typically within a few hours depending on the volume of queries).
The Removal Tools work best when used in conjunction with the noindex directive. Remember that any deletions you make are reversible in the future.
g. Use Meta Robot Tags and X-robots
An HTML document can add a robot meta tag to offer information about a single page without affecting the site-wide robots. This gives you more control over how each page is crawled.
It can also include instructions for specific crawlers (“Google bot” or “Bing bot”) and omit pages from Google Images, Videos, and News searches. One must use a meta robots tag on pages that you do not want search engines to crawl.
If you inadvertently add a noindex tag to a page that should not be indexed according to your robots.
The X-Robots tag appears in an HTTP header response. It serves the same purpose as a meta robots tag, controlling the indexing of photos, videos, PDFs, and other non-HTML documents.
h. Implement Pagination Properly
If your website has paginated material (such as product listings or article archives), use the rel=”next” and rel=”prev” tags to indicate appropriate pagination to search engines.
This stops them from indexing each paginated page individually, which reduces index bloat.
Conclusion
Index bloat is a prevalent issue that impacts a website’s performance in search engine results pages and user experience.
Excessive indexing of irrelevant sites by search engines buries useful material. This leads to diluted rankings and wasted crawl resources.
However, recognizing the causes and implementing appropriate technological remedies can improve overall SEO performance.
You can identify which pages on your site have index bloat and eliminate them using the techniques discussed above.
This can help you improve your site’s overall quality evaluation in search engines, rank higher, and create a cleaner index, allowing Google to identify the pages you want to rank fast and effectively.
Frequently Asked Questions
This occurs when search engines such as Google index a huge number of irrelevant, redundant, or low-quality pages from a website. Index bloat can dilute a site’s SEO efforts by spreading the crawl budget unevenly and influencing search engines’ overall quality evaluations.
This issue happens when you directly ask Google to index a page (by adding it to the sitemap or manually requesting indexing), yet that page has no index tag. The remedy is simple: delete the noindex tag so that Google may access the page.
To prevent URLs or domains from showing in Google search results, use a noindex tag in the header of the page(s) you wish to delete. Deindexing is the process of removing an existing URL from Google’s search index.


