Last Updated on 26/10/2025
If you operate a website, you undoubtedly want it to appear in Google’s search results.
What’s the use of having a website if nobody can discover it?
Unfortunately, things can go wrong, and your site may not appear in Google search results even if you have done everything correctly. One possible explanation is that your website pages have been identified as “discovered – currently not indexed” in Google Search Console.
Do not worry, though!
In this knowledge base article, we’ll explain what this message means and offer suggestions for resolving it.
What does the “Discovered- currently not indexed” status mean?
The phrase “discovered – currently not indexed” refers to two things. One, Google found your page. Two, Google has not yet crawled and indexed your webpage.
Google’s Search Console support page explains why:
“Typically, Google wanted to crawl the URL, but this was expected to overload the site; therefore, Google rescheduled the crawl. This is why the last crawl date is empty on the report.”
This does not imply that your material will never be crawled and indexed. According to Google’s guidelines, It may return to crawl your website after you take no action.
However, Google’s postponement of the crawl is only one of numerous possible causes of this issue.
Explore the causes of “Discovered ‐ currently not indexed” and how to enhance your SEO.
7 Tips On How To Fix “Discovered Currently Not Indexed” Status
1. Request Indexing
If you observe only a few pages with the “Discovered – currently not indexed” issue, consider requesting indexing via Google Search Console. To accomplish this, select “URL inspection” from the menu, then enter the page’s URL. If it is not presently indexed, use the “Request indexing” button.
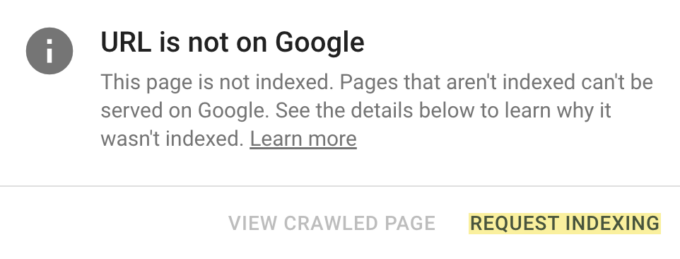
Also, if everything is OK, you should get a notice indicating that the URL has been placed to the priority crawl queue.
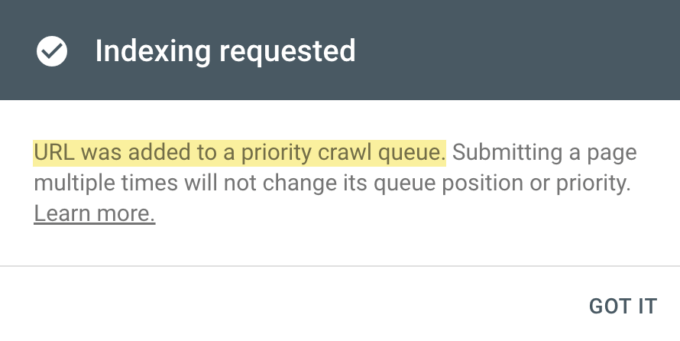
If this does not work, there is usually always an underlying issue that must be diagnosed and resolved before requesting indexing again. So continue reading.
2. Follow Internal Linking Best Practices
Googlebot uses internal links to discover and comprehend the relationships between your site’s pages. Internal links also help distribute PageRank, a ranking signal.
Assume Google does not locate enough links pointing to a URL. In that instance, it may forgo crawling owing to inadequate signals indicating its relevance. Google may consider pages with few internal links irrelevant. As a result, some pages may have the status “Discovered – currently not indexed.”
Proper internal linking entails connecting your pages to form a logical structure. This structure enables search engines and people to comprehend the hierarchy of your pages and how they are linked.
By effectively implementing internal linking, you help Googlebot find all your content and improve your chances of ranking higher. Linking internally to unindexed pages enhances their chances of being picked up by Google when resolving “Discovered ‐ currently not indexed” issues.
Some of the recommended practices for internal linking are:
- Decide on your main content and connect to it from other pages.
- Use contextual links throughout your article.
- Pages should be linked according to their hierarchy, for example, core pages to supplemental pages and vice versa.
- Do not flood your website with links.
- Don’t overoptimize your anchor text.
- Add links to similar items or posts.
- Include internal links on unintended orphan pages.
3. Check For Content Quality Issues
Google does not index everything it discovers. It prioritizes high-quality, distinctive, and interesting information. Because Google has not yet crawled pages containing this warning, it cannot determine whether the content is low quality. However, based on comparable pages crawled before, it may have “deprioritized” crawling.
Here are some examples of content that Google is unlikely to index:
- Machine-translated material – If you use Google Translate API or a similar tool to localize content, the translations will be far from flawless. In this scenario, it isn’t very valuable to searchers.
- Spun content- It refers to the process of rewriting material using software. The end product is nearly always poor-quality, copied stuff.
- AI-generated content – AI writing tools are becoming more popular, yet they seldom produce usable material without human intervention.
- Thin content – These are pages with little distinctive material.
If any of these are applicable to your material, utilize the flowchart below to resolve the issue:
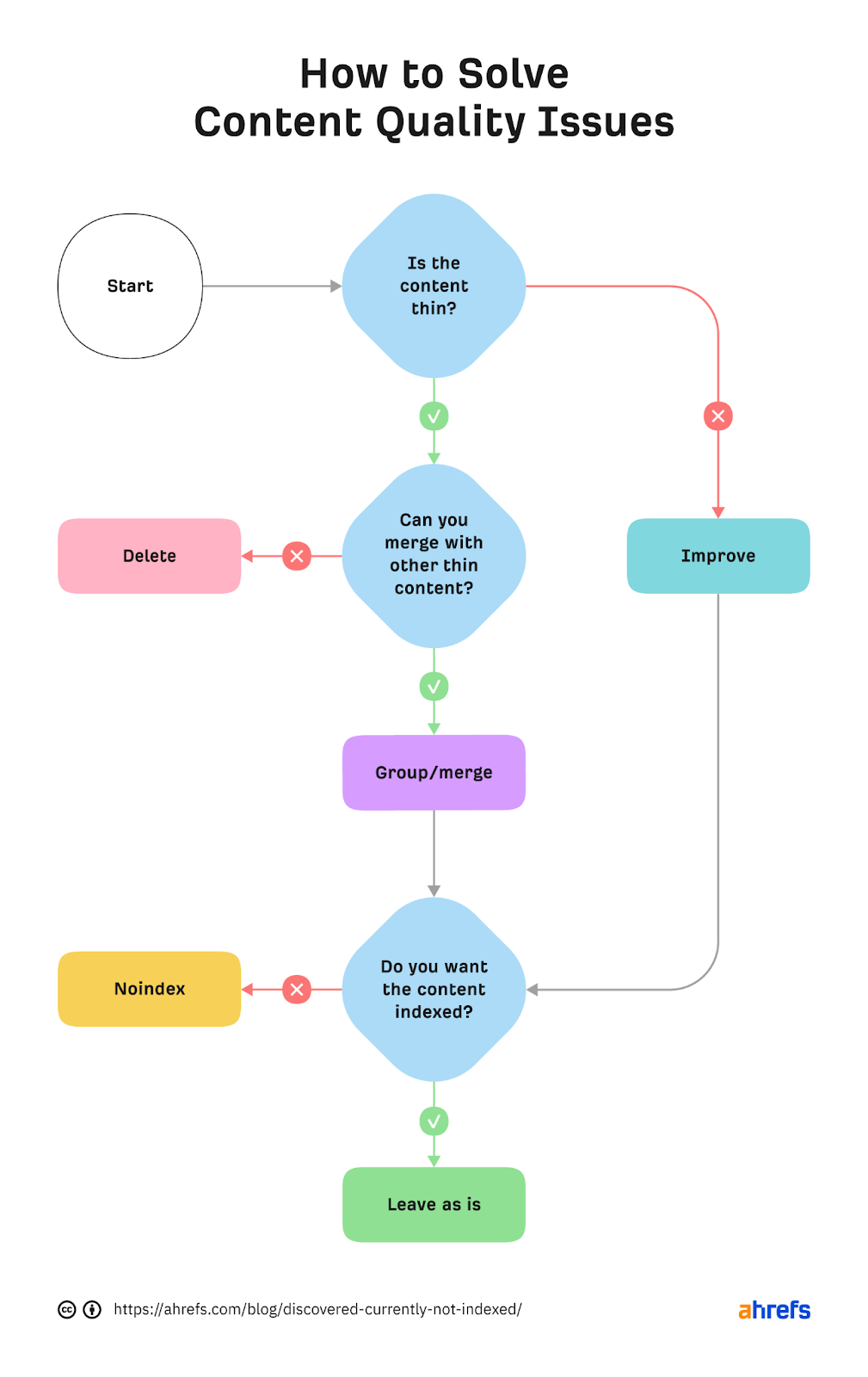
In summary, if you have thin material, either combine it with other thin content to make something helpful or erase it. Otherwise, enhance the material. If the generated material isn’t optimized for organic search, no-index it so search engines may focus on crawling other essential sites.
4. Create An Optimized Sitemap
An optimized sitemap can help Googlebot navigate the crawling and indexing process. It is simply a map that Google can use to navigate your information.
A sitemap should include:
- URLs returning 200 (OK) status codes.
- URLs without meta robots tags are not indexed.
- Only the canonical versions of your pages.
5. Crawl Budget Issues
The Discovered-Currently Not Indexed notice might also be caused by a crawl budget. We’re all aware that Google has limited resources to crawl all sites on the internet, and it prioritizes spending those efforts on the most essential pages on your website.
However, if Google scans all of your site’s URLs, including low-quality sites, your valuable pages may not be crawled thoroughly. Crawl funding concerns mostly affected larger sites, but they also affected smaller sites due to technical issues.
6. Check Backlinks
Backlinks are one of the factors Google uses to determine whether a page is useful and worth indexing. If your website has no or few high-quality backlinks, this might be one of the reasons Google “deprioritized” crawling.
Getting additional backlinks is perhaps the most difficult of the tasks outlined, but it pays off. Even a single valuable connection can help Google identify and index your content more quickly.
7. Fix Redirects
You should prevent redirect chains and loops.
The divert chains are used when you wish to divert traffic from page A to page B without first redirecting to page C.
Redirect loops occur when you create a redirect chain that starts and ends on the same page, trapping users and bots in an infinite loop.
Both redirect chains and loops cause Google to perform repeated, needless queries to your server, which reduces your crawl budget.
In addition, if your redirects do not operate properly, they may appear in Google Search Console with the status “Redirect error“.
Avoid linking to redirected pages to save your crawl budget. Instead, change them to point to 200 OK sites.
Wrapping Up
URLs under “Discovered ‐ currently not indexed” are due to site quality, internal link structure, and crawl budget constraints.
Here are some essential elements that might help your website be crawled and indexed:
- Examine the quality and originality of the pages you impacted.
- Apply internal links, particularly to important pages.
- Use robots.txt to keep Googlebot from crawling low-quality pages.
- Have an indexing system in place that prioritizes the most essential pages.
- Optimize your crawl budget so that Google can crawl these sites more efficiently.
FAQs
“Discovered currently not indexed” in Google Search Console indicates that Google found the page during crawling but chose not to index it. This status suggests that there may be issues preventing the page from being included in Google’s search index, impacting its visibility in search results.
Diagnosing the reasons for pages being “discovered, currently not indexed” involves examining potential issues such as crawlability, indexability, and content quality. Review factors such as robots.txt directives, meta robots tags, canonicalization, duplicate content, and manual actions in Google Search Console to identify any obstacles to Google indexing.
To address “discovered currently not indexed” issues, focus on improving crawlability, indexability, and content quality. Remove crawl-blocking directives, ensure unique and relevant content, optimize meta tags, and request indexing through Google Search Console. Monitor progress and make adjustments to maintain indexation and improve search visibility.


